清册系统是用于公司硬件工程师分类登记硬件元器件的工具,属于行业性非常强的工具,功能并不复杂,旨在提供填写录入元器件信息并提供查询。
项目采用Python Django框架,前端使用AdminLTE v3.2.0,数据库Mysql 8,由于是个小系统,一个人开发和后续的维护,也不需要考虑前后端分离。
一、 物料新增
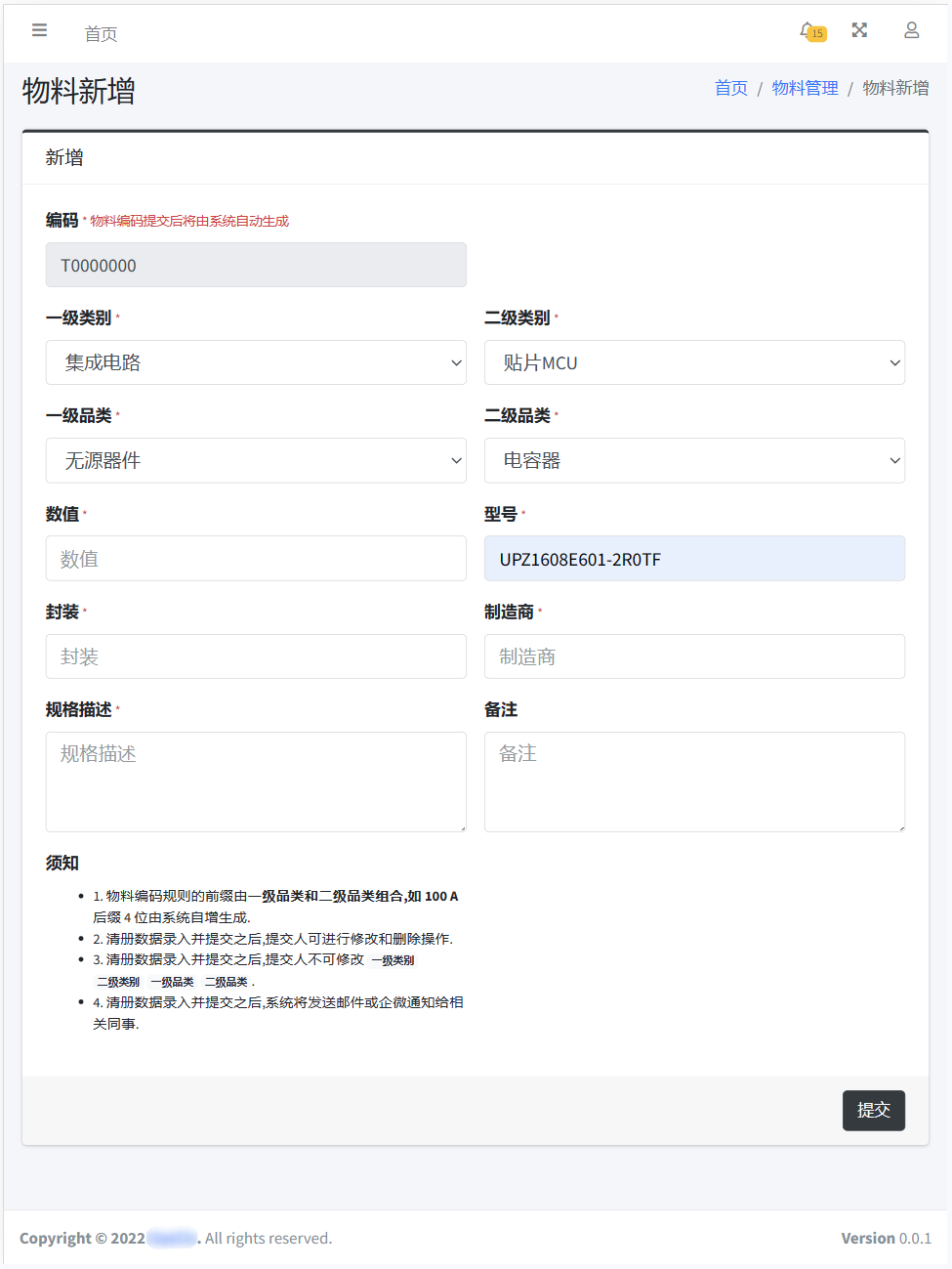
物料新增页面实现硬件工程师按分类录入电子元器件信息以及自动按规则生成编码的功能,一级分类、二级分类和一级品类、二级品类都是级联选项,它们决定了最终编码的生成规则。
二、 物料分类
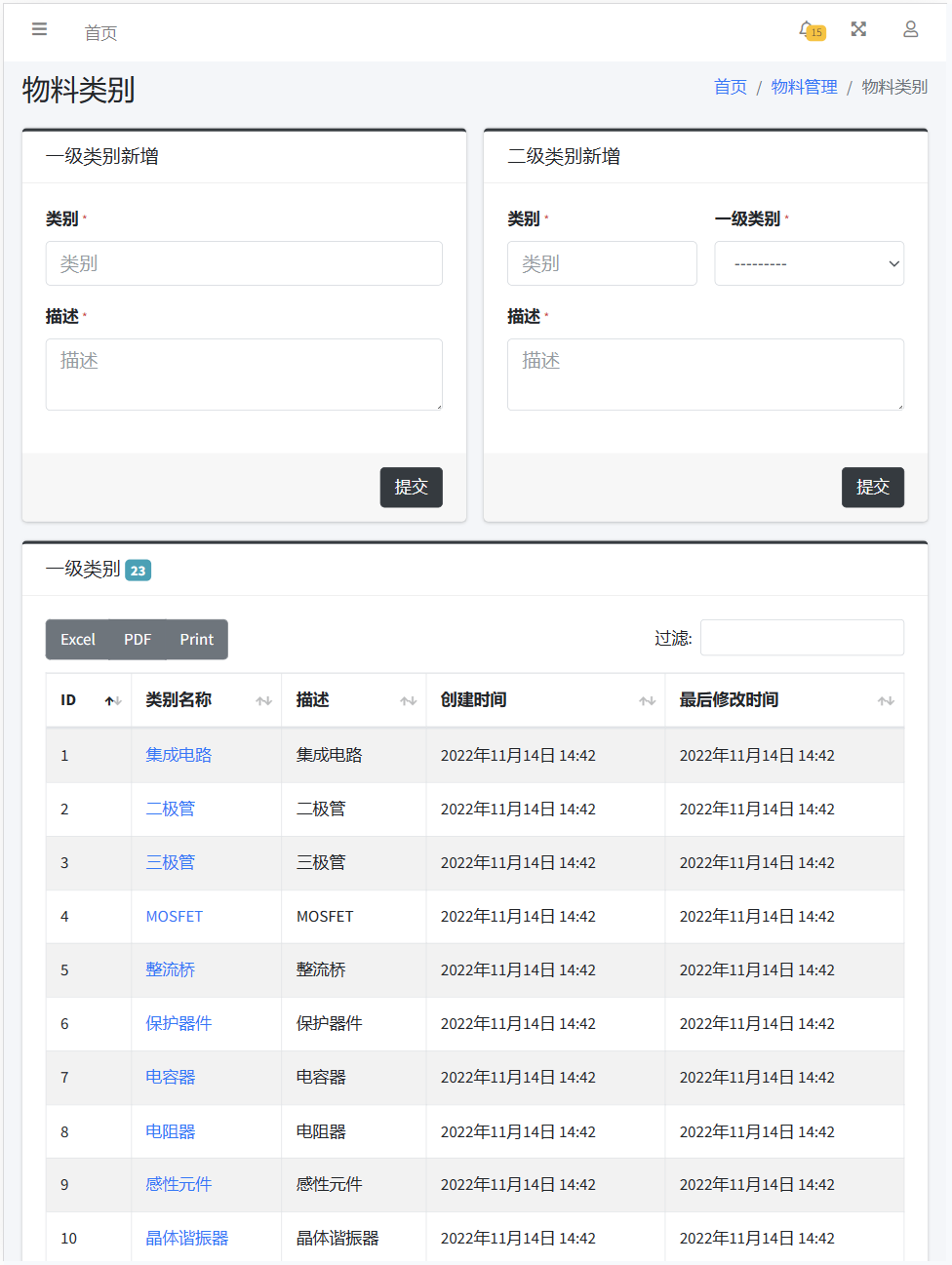
物料分类页面实现一级分类和二级分类的创建,页面分别由两个表单和列表组成。
三、 物料品类
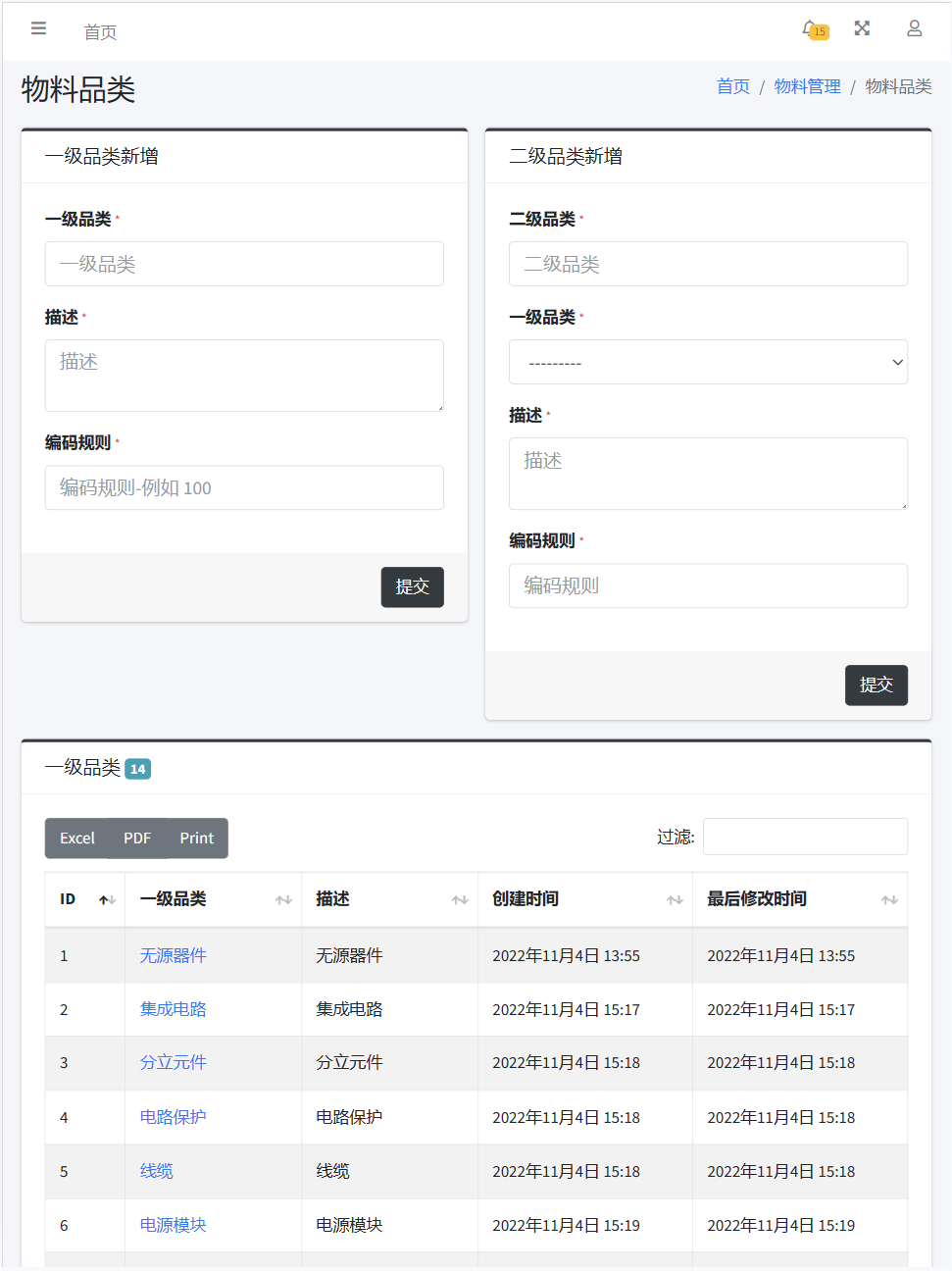
物料品类页面实现一级品类、二级品类的创建,页面分别由两个表单和两个列表组成,它们决定了物料新增到系统之后的编码前缀。
四、 物料列表
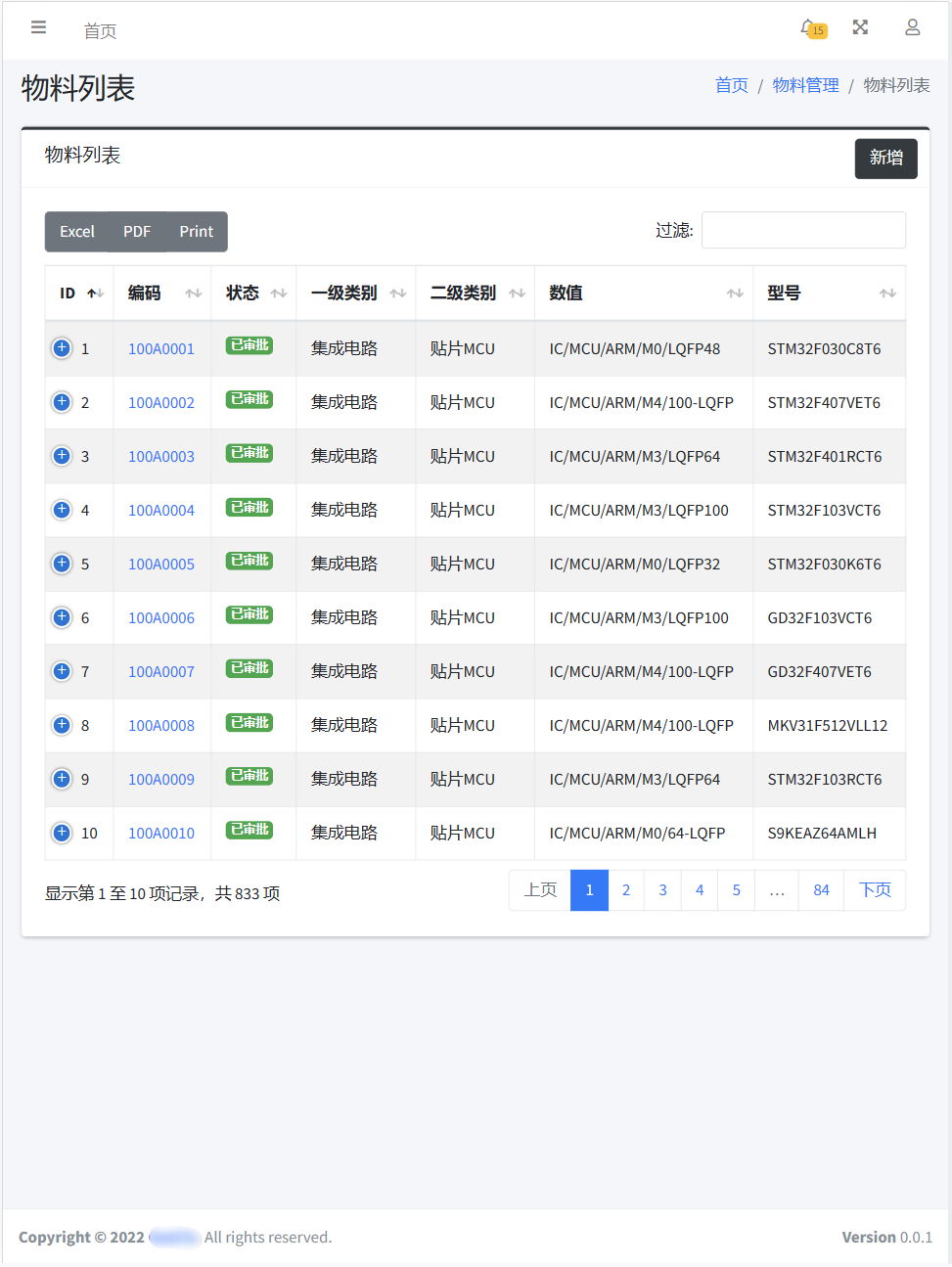
物料列表页面用于展示所有的数据,点击编码,可进入详情页面(如下图)
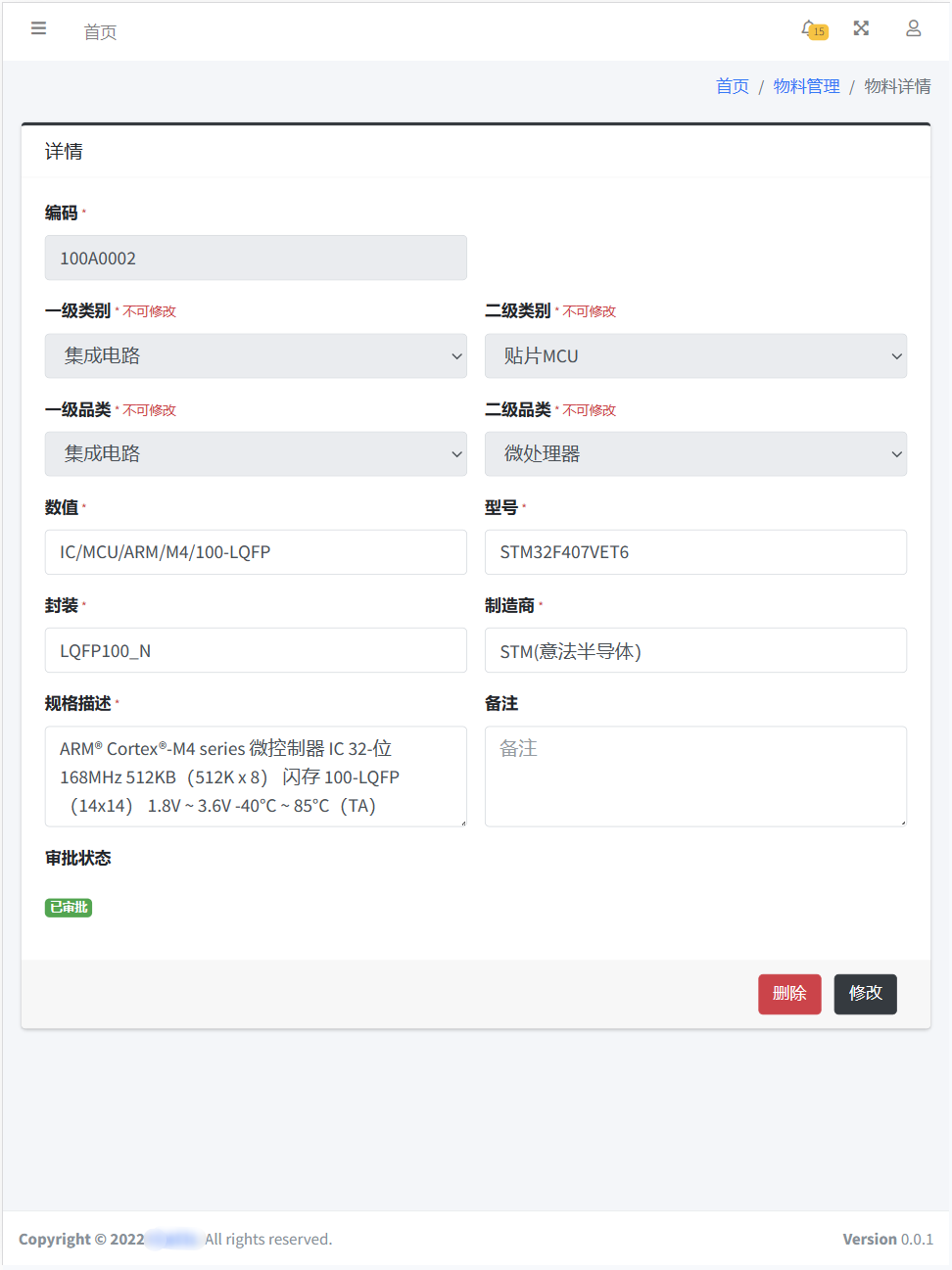
详情页提供对单物料进行修改和删除操作。
五、 数据初始化
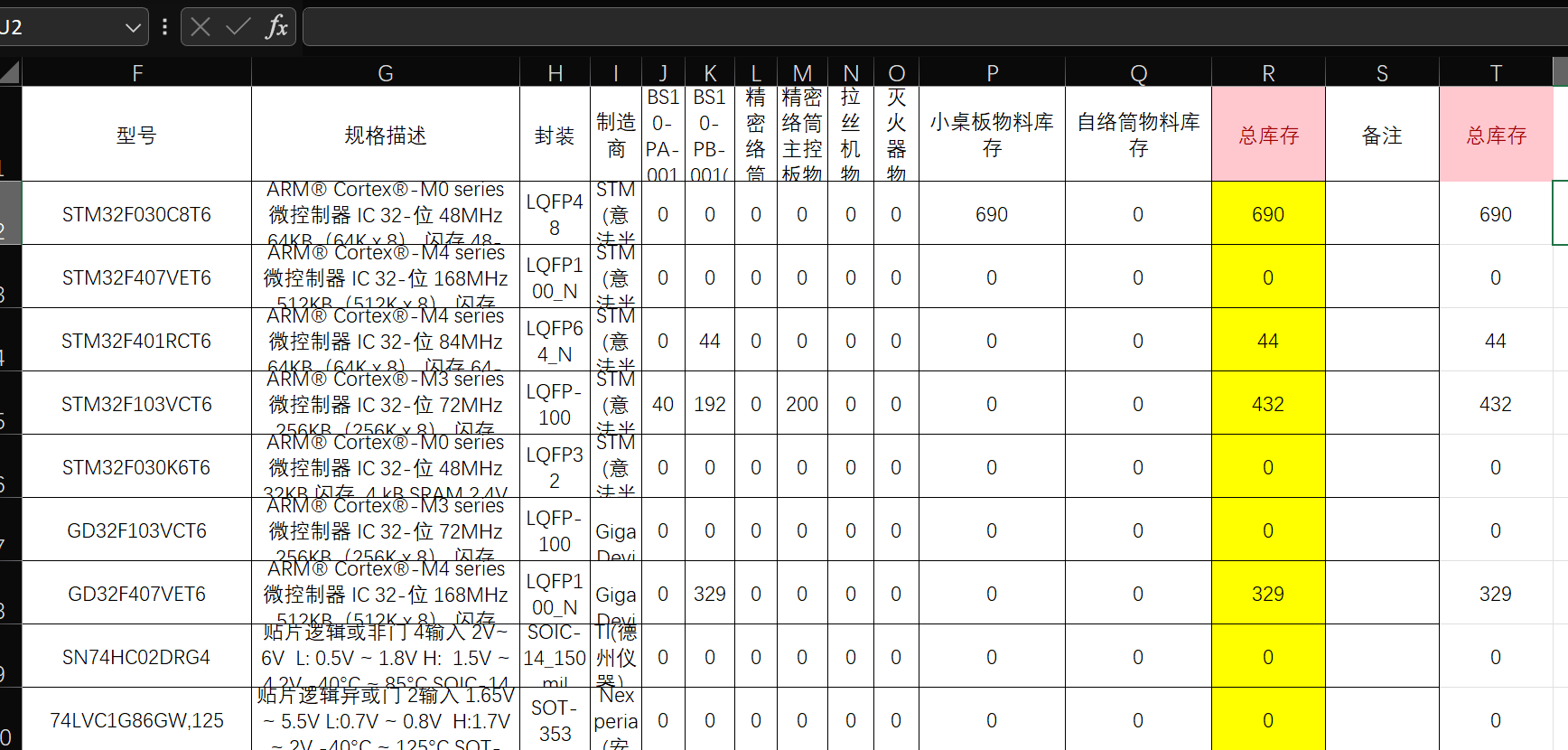
在清册系统没有上线前,硬件的同事都是使用Excel去管理硬件元器件数据的,也包括编码生成,使用系统时需要进行一次数据的初始化,读取Excel数据存入数据库即可,脚本在Django项目内,而且需要调用几个数据Model,所以少不了os.environ[‘DJANGO_SETTINGS_MODULE’] = ‘gatcis_ms.settings’这句。
from io import BytesIO
import os
from datetime import datetime
import time
import xlwt, xlrd
import django
os.environ['DJANGO_SETTINGS_MODULE'] = 'gatcis_ms.settings'
django.setup()
from material.models import AmlModel, BigTypeModel, SmallTypeModel, ParentCategoryModel, SubCategoryModel
def import_excel():
wb = xlrd.open_workbook(filename=r'C:\Users\zheng\PycharmProjects\gatcis_ms\aml.xls')
print("读取Excel")
table = wb.sheets()[0]
rows = table.nrows
counter = 1
err_list = []
try:
if rows > 1:
for i in range(1, rows):
row_values = table.row_values(i)
print("-----------------")
pn = row_values[0]
if pn_unique(pn):
err_list.append(pn)
print(err_list)
continue
parent_name = row_values[1]
sub_name = row_values[2]
pid = parent_select_insert(parent_name)
aml = {
"pn": pn,
"parent_category_id": pid,
"sub_category_id": sub_select_insert(category_name=sub_name, pid=pid),
"big_type_id": big_query(pn=pn),
"small_type_id": small_query(pn=pn),
"product_value": row_values[3],
"item_no": row_values[4],
"specification": row_values[5],
"package": row_values[6],
"maker_brand": row_values[7],
"status": True,
"is_show": True,
"remark": row_values[8],
"created_on": datetime.now(),
"modify_on": datetime.now(),
}
print(aml)
AmlModel.objects.create(**aml)
counter += 1
start_line = '\033[1;31m '
end_line = '\033[0m'
print(start_line + "第 {c} 行数据录入成功".format(c=counter) + end_line)
print("-----------------")
print("当前插入数据共计 {c} 条".format(c=counter))
print("重复的PN编号:", err_list)
except Exception as e:
return e
def parent_select_insert(category_name):
try:
parent = ParentCategoryModel.objects.filter(title=category_name).first()
if parent:
print("一级类别已经存在")
return parent.id
else:
print("一级类别不存在")
parent = {
"title": category_name,
"description": category_name,
"created_on": datetime.now(),
"modify_on": datetime.now(),
}
p = ParentCategoryModel.objects.create(**parent)
print("插入一级分类")
print("parent_id: {id}".format(id=p.id))
return p.id
except Exception as e:
return e
def sub_select_insert(category_name, pid):
try:
sub = SubCategoryModel.objects.filter(title=category_name).first()
if sub:
print("二级类别已经存在")
return sub.id
else:
print("二级类别不存在")
sub = {
"title": category_name,
"description": category_name,
"created_on": datetime.now(),
"modify_on": datetime.now(),
"parent_id": pid,
}
s = SubCategoryModel.objects.create(**sub)
print("插入二级分类")
print("sub_id: {id}".format(id=s.id))
return s.id
except Exception as e:
return e
def big_query(pn):
big_type = BigTypeModel.objects.filter(code=pn[:3]).first()
print("获取一级品类成功")
return big_type.id
def small_query(pn):
big_type = BigTypeModel.objects.filter(code=pn[:3]).first()
small_type = SmallTypeModel.objects.filter(code=pn[3], big_type=big_type.id).first()
print("获取二级品类成功")
return small_type.id
def pn_unique(pn):
pn = AmlModel.objects.filter(pn=pn).first()
if pn:
start_line = '\033[1;31m '
end_line = '\033[0m'
print(start_line + "PN {pn} 重复".format(pn=pn) + end_line)
return True
# 求一次成功,不报错
import_excel()六、 部署
由于公司有阿里云的Windows Server,代码托管在IIS上。
七、 总结
整个小项目当时好像只用了一个星期,这还包括了重新翻看Django官方文档,毕竟不是不停重复写一个Django框架,难免会在用时重新翻文档。
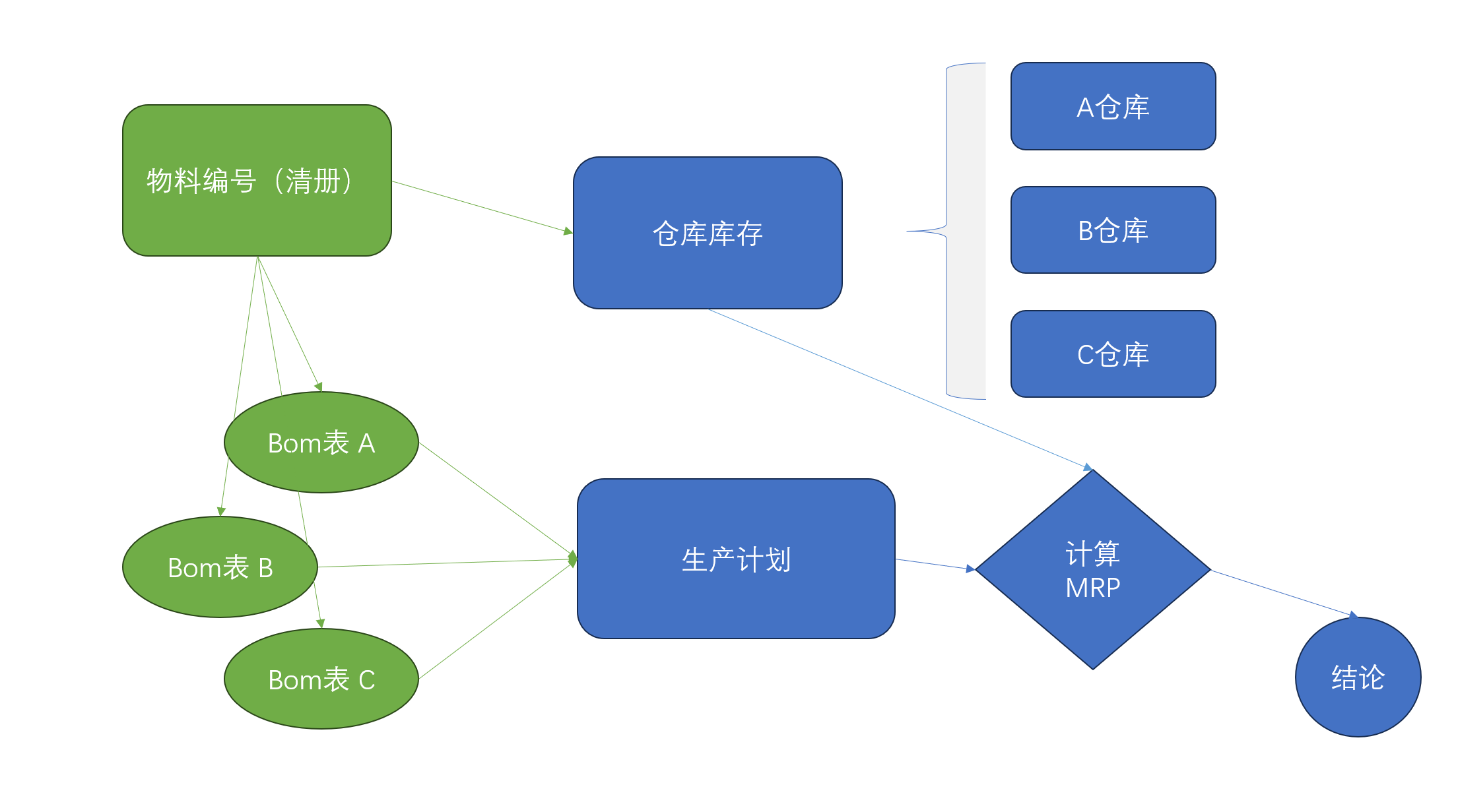
清册小工具能够解决硬件工程师录入元器件信息、生成编码,以及数据的共享,它作为一个输入端向后或向上还可以接入到Bom、仓库、ERP等等,系统的推进本质上依赖需求推动,每个公司不同的发展阶段对于工具的需求和定义都不同,实际践行的每一步都非易事。